ابتدا چندین مفهوم که کلی ترن رو تعریف می کنم ، سپس مراحل طراحی یه سیستم رو مانند مصاحبه ها طی می کنیم
system design terms
circuit breaker pattern
در صورتی که یکی از سرویس ها یا کامپوننت ها down شد یا پاسخ ها با تایم اوت بر میگشت ، همه ی درخواست ها رو نفرستیم که خطا رو هر بار نمایش بدیم ، همون اول جلو ورود درخواست رو می بندیم که منتظر پاسخ خطا از سوی سرویس نباشیم ، همچنین ۳ حالت دارد ، حالت باز که پاسخ ها موفق هست ، حالت بسته که درخواست دیگه نمیره به سرویس ، حالت نیمه باز که با یه لاجیکی در بازه زمانی ، تعدادی پاسخ محدود میفرستیم ، اگر درست شده بود ، باز میکنیم
back-off
خیلی شبیه بالایی هست و هدفش اینه که در صورت قطع ارتباط بار روی نتورک نندازیم
مانند تلگرام اول بعد یه ثانیه دوبار درخواست کانکشن میزنیم ، بعد بعد ۳ ثانیه و با الگوریتم مورد نظر زیادش میکنیم
chatty io
میگه تا جایی که ممکنه کانکشن های زیاد نزنیم برای گرفتن داده ها از یه منبع بجاش از بچ یا بالک یا … استفاده کنیم ، به تعریف دیگر هر در خواست به خارج از سرویسمون ، خارج از گو نیاز به کانکشن و io داره باید اونها رو بهینه کرد
نحوه سنجش عملکرد کد
Latency
مدت زمان بین درخواست و پاسخ چند ثانیه است
Troughput _ rps
چه تعداد درخواست رو میتونه هندل کنه
load test
برای این منظور از load test , stress test استفاده میکنیم
یکی از ابزار های خوب apache bench mark است
همچنین میتونیم از ابزار locust استفاده کنیم ، گرافیکیه ، اطلاعات رو ذخیره میکنه و به صورت کانکارنسی تمام core ها رو درگیر میکنه
می توان latancy رو چند حالت اندازه گیری کرد ابتدایی ترین راه ، میانگین است یعنی مجموع ریکوست ها تقسیم بر تعداد اما راه بهتر upper 90 , upper 99 است
معیار های قابل اعتماد بودن - Design for Reliability
- Redundancy داده ها در جای دیگر هم باشند در صورتی که مسیر اصلی پایین آمد ، بشه از جای پشتیبان داده ها رو خوند
- Graceful Degradation در صورتی که بخشی ترکید ، همه ی اکوسیستم نترکه و تنها اون بخش از کار بیفته
Scaleup
vertical
در این حالت تنها single instance داریم و بهش cpu . Ram . Hard بیشتر میدیم
معایب
-
در صورتی که بخواییم سخت افزاری اسکیل آپ کنیم باید از دسترس خارج شه ، توجه شود اگر پیک درخواست داشته باشیم نیازه پول به ریسورس بدیم ، اما در صروتی که نمی خواییم هم هزینه ی اونا رو دادیم و نمی تونیم کاهش بدیم
-
اگر ماشین بترکه ، همه چی میاد پایین و نابود میشه
horizontal
در این حالت تعداد instance هامون رو بالا میبریم
Leader election
در سیستم های توضیع شده ، همواره مستر اسلیو وجود دارد ، در صورتی که node leader ترکید ، یکی از الگو ها ، انتخاب نود مستر است و چند الگوریتم معروف برای انتخاب مجود دارید :
-
Bully Algorithm هر نود ریسورس بهتری داشت یا شناسه یا IDبالا تری داشت
-
Raft/Paxos واقعن رای گیری می کنن
-
ZooKeeper یه ابزار هست و این کار رو میکنه
Auth Messages in Microservices
trust zone
در میعماری به محدوده ای که می دونیم داده در صورت ورود صحیح _ valid _ است و نیاز نیست در تمامی میکرو سرویس ها هر بار داده چک ولید شود می گویند
zero trust
به علت اهمییت زیاد و این که مطمعن باشیم علاوه بر چک سرویس درخواست کننده ، خود هم دوباره از صحت داده مطمعن شویم ، دوباره ولید بودن داده را چک میکنیم و یعنی به هیچ سرویسی اعتماد نداریم
یه رویکرد امنیتیه که میگه بر خلاف دید سنتی ، تنها هنگام ورود از صحت چک نشه بلکه در هر سرویس خواست استفاده بشه ، چک بشه و جمله ی معروف :
never trust, always verify
tokens
یکی از راه های خوب برای احراز هوییت ، اینه که در هر مرحله که امنیت مهم است ، توکن درخواست را ولید کرده و با استفاده از اطلاعات غیر مستقیم توکن ، درسترسی را چک کنیم
مثال
توجه شود gateway تنها میتواند توکن رو چک کنه ، مثلن وقتی درخواست تنها بر اساسه uuid باشه ، نیازی نیست دابل چک بشه چون احتمال تولید چنین شناسه ای صفره ، ولی وقتی درخواست دریافت اطلاعات فلان کد ملی میشه ، علاوه بر چک gateway , باید سرویس دوباره چک کنه کاربر می تونه این درخواست رو بزنه یا نه تنها چیزی که gateway تولید میکنه ، metadata هست و میشه به آن اطمینان کرد و با استفاده از این ، درخواست های دابل چک کرد ، به نظرم وظیفه ی ولید بودن درخواست در لایه ی یوزکیس نیست ، در لایه ی دلیوری یا فریمورک است
Disaster Recovery
در برابر خرابی و سوختن سرور ها یا کرش کردن مقاومه و حتی بعد از از دست دادن دیتا ها ، بشه برگردوند
Centralized Decentralized Distributed Systems
- Centralized
تمام سیستم و پردازش ها روی سینگل سرور یا ماشین هستند
-
- سینگل پوینت
-
- مدیریت و نگهداری آسان
-
- امنیت بالا تر و ساده تر
-
- زمانی که منابع محدود میشه مشکل خیلی سخت برطرف میشه
-
Decentralized
تمام پردازش در یک ماشین یا سرور نیست اما مدیریت نود ها مشخص است ، بین پاد ها یکی باید مستر باشد برای سینک و منیج
-
- سرور ها مستقل هستند
-
- مدیریت سخت تر است
-
- منابع میتونه بیشتر بشه
-
- خیلی نقش مستر یا لید مهمه
-
Distributed
پردازش در یک ماشین نیست و مدیریت هم خیلی جدی و ثابت نیست ، هر پاد گاهی میتونه مستقل کار کنه گاهی هم می تونن بین پاد هایی که بالا هستند ، خودشون یک یا چند مستر انتخاب کنند
-
- سرور ها مستقل هستند
-
- مدیریت خیلی خیلی سخته و باید الگوریتم های خفن کوردینت و هندل کردن پاد ها رو به خوبی پیاده کنیم
-
- کاملن اطمینان از استقلال پاد ها و مستقل بودن
CDN (Content Delivery Network)
برای کاهش تاخیر داده ها در چند سرور تقسیم میشوند ، به بیان دیگه سرور هایی توزیع شده تو شبکه اینترنت که داده های استاتیک رو کش کرده و با سرعت بالا برای یوزر با توجه به ریجن سرو می کنه مانند عکس فیلم و فایل های استاتیک ، همچنین لود از روی سایت ما برداشته می شه
Trade-offs
-
latency and throughput درصورتی که منابع ثابت است و درخواست ها زیاد یا باید جواب همه رو با تاخیر بدیم یا محدود کنیم درخواست ها رو
-
Complexity and Maintainability هر چه قدر بخوای کد های پیچیده تر و خفن تر بزنی و فیچر خفن اضافه کنی ، نگه داری هم سخت تر میشه
-
CAP theorem توجه شود این برای دیستریبیوتد سیستم ها - دیتابیس ها - هست و نه برای سرویس ها
همیشه باید یه تعادلی بین ۳ مفهوم زیر ایجاد کرد consistency, availability, and partition tolerance
-
- consistency میگه اگر چند نود داشته باشیم همه ی داده ها در نود ها بروز و یکسان باشد و درصورتی که در خواست بزنیم هر نود که جواب دهد ، داده بروز باشد ، اگر این قابلیت رو پایین بیاریم شاید هر درخواست از نود های مختلف ، پاسخ های نامساوری برگردونن ، توجه شود اگر دیتا دیستریبوتد ها در regional های مختلف باشد ، شاید تا یک ساعت ، یا ۸ ساعت سینک نباشند برای مثال کساندرا این رو نداره
-
- Availability پاسخ بده حتی اگه پاسخ درست نباشه ، یا پاسخ درست بده ، یا پاسخ قدیمی بده ، یا پاسخ اشتباه ولی بی پاسخ نزاره ، برای مثال mongo این رو نداره
-
-
Partition tolerance حتی اگر یکی از پارتیشن ها از دسترس خارج شد ، بقیه به کار خودشون ادامه بدن ، اگر بخوایم این رو حفظ کنیم باید ثبات یا دردسترس بودن رو زیر پا بزاریم ، برای مثال دیتابیس هایsql distribiuted(sharding) این رو ندارن
-
ثبات در ایجاد یک سطر مهم
Single-Writer
یعنی توی یه سیستم کلا یک موجودیت حق نوشتن داره. این موجودیت میتونه Leader باشه توی یه کلاستر. همهی درخواستهای INSERT/UPDATE/DELETE باید به همین Leader برسن. چرا؟ چون اینطوری ترتیب همهی تغییرات مشخص و قطعی میشه در حقیقت مشکل رپلیکا اینه که کمی عقبه و بهتره برای خوندن های خیلی مهم از لیدر استفاده بشه و برای خوندن های ریپورت و فیلتر و آرشیو از رپلیکا استفاده بشه
read-your-writes consistency
برای اینکه این اطمینان رو به کاربر بدیم که چیزی که نوشتی ثبت شده بهش آیدی سطر ثبت شده رو میدیم علاوه بر اون می تونیم ورژن هم بدیم
وقتی کلاینت چیزی مینویسه، Leader یه version/LSN/token برمیگردونه.
اینجوری کاربر هم آیدی رو می ده هم ورژن و پاسخ می تونه هم از لیدر دریافت بشه و هم از رپلیکایی که تا اون ورژن سینک شده
Transactional Outbox
TODO
TCC
TODO
system design interview
تعریف
به تعیین معماری نرم افزار ، واسطه ها ، زیر ساخت ، تکنولژی ، داده ها و نحوه ی ارتباط آن ها با توجه به نیاز های بیزینس می گویند
requirementsw
در ابتدا فقط نیازمندی هاشو مصاحبه کننده میپرسه ، بیشتر شبیه به نیاز های پروداکتی ، نیاز های اکتور
اگر این بخش رو نگفت یا خیلی خیلی کلی گفت ، این وظیفه ی ماست که با پرسش و پاسخ نیاز ها رو در بیاریم
data gathering
با این که شاید خیلی ساده طرف بگه سیستم دیزاین آپارات رو بده ، یا سیستم دیزاین چت رو بده ، ولی ما نباید گول بخوریم و همش باید جزییات رو ازش بپرسیم
- actor
یکی از اطلاعاتی که احتمالن نیاز باشه اکتور ها هستن و باید پرسیده شه
برای مثال باید بپرسیم آیا کلاینت ما تنها یوزر است ؟ آیا ادمین هم دیده شه ؟ مثال :
-
- consumer
-
- producer
-
- admin
-
action - functional requirements
بعد از این که اکتور ها مشخص شدن ، باید لیست اکشن هاشون رو در بیاریم ، مثلن فروشنده می تونه کالا رو انتخاب کنه یا فروشنده می تونه به تعداد کالا بیفزایه
-
- producer : create item
-
- consumer : get list item
نکته بعد از در آوردن اکشن ها باز باید بپرسیم به نظرت کافیه یا چیزی از قلم نیفتاده؟
در بیشتر آموزش ها این ها در نهایت همون http api ها میشن
- non functional requirements
سوالات فنی و زیرساختی مانند اینکه برای چه تعداد کاربر طراحی میشه، تعداد همزمان در بیشترین حالت چقدر هست ، سرور ها متمرکز هست یا در چند جا هست ؟
-
- تعداد کاربرا؟ برای لیتنسی و تروپوت
-
- مثلن اگر فروشگاهیه ، باید خرید ، ریل تایم نمایش داده بشه ، ولی امتیاز یک کالا یا نظرات نیاز نیست ریل تایم باشه
-
- نسبت write به read در صورتی که خیلی تفاوت باشه میتونیم از cqrs استفاده کنیم
-
- میتونیم بپرسیم حجم هر پیام در توییتر یا عکس در اینستاگرام
-
- تعداد درخواست ها در ماه
Persistent storage
در این مرحله دیگه سوالات پرسیده شده تقریبن نیازمندی های پروداکتی در آورده شده ، حالا میریم سراغ ساختار ذخیره سازی ، توجه شود دیدمون جوری باید باشه که اینگاری تیبل های یه پروژه کوچیک رو داریم می کشیم ، ولی هر کدوم در عمل جدا هستن
مثال
-
profile
-
wallet
-
comment
-
like
-
stock
-
object-storage(minio) images/iiiprofile
حالا باید هر دیتابیس بالا رو مشخص کنیم sql هست یا nosql و دلیلش هم بگیم
احتمالن هر داده ای که ساختار مند بود sql هست ، دلیل بعدی برای انتخاب sql ها کوییری زدن مشخص هست روی دیتا ، مثلن اگر بخواهیم چند کوییری پیچیده بزنیم ، رو داده ثابت ،اینا فرفورمنس بهتری دارن
در بیشتر آموزش ها جدول دیتا مدل ها رو خیلی شبیه به دیاگرام طراحی دیتابیس میکشن
در این جا می تونیم به علاوه موارد بالا ، بقیه ی entity ها رو هم بگیم ، مثلن شاید داده ای نقطه ی جغرافیایی باشه ، شاید داده ی جنریت شده ی spark باشه و موارد بالا هیچ وقت یه تیبل نشن ، ولی موجودیت هستن
sharding
-
shard key یه فیلد است که مخصوص شارد است و سوای id و فیلد های دیگه توی تیبل عادی است ، با استفاده است این فیلد می تونیم هر شارد را ایندکس کنیم
-
gloabal index بر خلاف لوکال ایندکس که هر تیبل جدا ایندکس کرده و شاید ایندکس یکان در ۲ تیبل جدا باشد ، در ایندکس سراسری اطمینان می دهیم که یک گلوبال ایندکس در تمامی نود ها یونیک است
کاربرد با استفاده از ۲ مفهوم بالا می توانیم یک لاجیک در نظر بگیریم که با استفاده از ID یک موجودیت ، آن در کدام شارد باید قرار بگیرد
و همچنین در زمان کوییری زدن می توانیم به جای کوییری بر روی تمامی شارد ها ، از شاردی که می دانیم داده در آن قرار دارد تنها کوییری بزنیم
Consistent Hashing algorithm
با استفاده از این الگوریتم معروف با اوجه به Hash Function می توانیم مکان هر id را درون دیستریبوتد دیتابیس پیدا کنیم
معایب
این که شاید بعضی سرور ها داده ی زیاد تری بره سمتش و عملن یک نواخت تقسیم نمی شه
قطعا برای طراحی شاردینگ باید یک شناسه را برا hash قرار دهیم و بیزینس طوری باشد که از جویین استفاده نشود اما در صورتی که بخوایم در داشبورد مدیریتی جویین بین داده ها بزنیم ، باید تمامی شارد ها جویین زده شود
یکی دیگه از مشکلات اینه اگر تعداد سرور ها فیکس نباشه یا به دلیل پایین اومدن یا به دلیل افزایش سرور ها ، توازن و هش های تولید شده شاید ترتیبشون تو کل نود ها تغییر کنه و اینجا مفهوم حلقه یا ring به کارمون میاد
ring
فرض کنیم ۵ سرور داریم و هر داده رو هش رو میگیریم و به ۵ تقسیم می کنیم تا ببینیم تو کدوم سرور باید بره . یک سرویس ترکید ، به جای این که باقی مونده داده ها رو تقسیم بر ۴ کنیم ، در ادامه هم روال قبل رو طی می کنیم اما اگر به سروری که ترکیده بخوایم داده بدیم ، به سرور بعدیش میدیم ، مانند حلقه اگر آخرین سرور ترکید ، چون بعدی نداره باید به اولی بدیم
می تونیم از ring virtual هم استفاده کنیم و به سرور بعدی نره و بعد از این که سرور ترکید دوباره اگر قرار بود برو تو سرور ترکیده ، تقسیم شه بین باقی مونده ها
replica
algorithm
- درخت مرکل - merkel tree - hash tree
کاربر ها
زمانی که مجموعه ای از فایل ها داریم و می خوایم در صورتی که فایلی تغییر کرد بفهمیم ، مثلن توی گیت استتوس کاربرد داره
زمانی باید توی رپلاکا چک کنیم که تمام نود ها سینک هستن
زمانی که یه فایل رو دانلود می کنیم و هر چانک اون جدا جدا میاد و می خواهیم چک کنیم که صحیح دانلود کردیم
Root
/ \
/ \
HashAB HashC
/ \
hashA hashB
در مثال بالا اگر ۳ فایل داشته باشیم ، دو به دو هش ها با هم جمع میشن و در نهایت هش روت مشخص میشه
اگر بعد از تغییرات بخواهیم در سریع ترین زمان ممکن بفهمیم کدام فایل ها تغییر کرده ، نیاز نیست همه ی فایل ها را بخوانیم
تنها کافی است از روت شروع کنیم ، اگر هش تغییر کرده باید ببینیم کدام فرزندان هشتتون تغییر کرده و با پیچیدگی زمانی O log n میرسیم به برگ ها یا فرزندانی که تغییر کردند
graph TD;
A[hashA] --> AB[HashAB]
B[hashB] --> AB
C[hashC] --> Root[Root]
AB --> Root
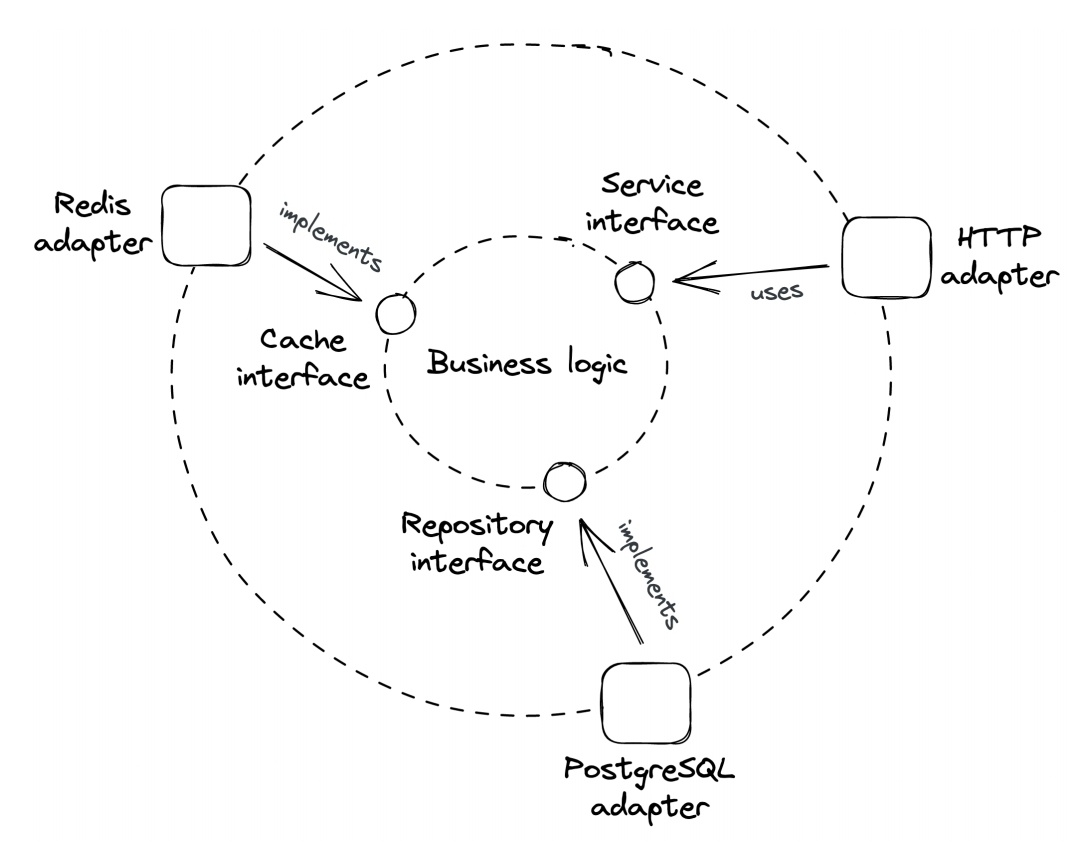
GateWay
در معماری میکرو سرویس بیشتر استفاده میشه و ابتدا درخواست به این کامپوننت میرسه و سپس میره به لود بالانسر
نکته
در این بخش می توان اختیاری مشخص کرد درخواست با http rest api هندل بشه یا websocket
در طراحی سیتم دیزاین این مولفه رو نمیبینن ، یا در کنار لود بالانسر میبینن
load balancer
یه کامپوننت توی سیستم هست که وظیفش اینه که ترافیک ورودی شبکه رو بین نود های ما تقسیم کنه تا بار رو دوش یه سرور نیفته برای افزایش پرفورمنت ، استفاده مفید از منابع و
توجه شود لود بلنسر درون خودش روتر سوییچ هم داره و به هر سرویس یه ip لوکال می ده
انواع
- لایه ۴ - Transport Layer
تنها ترافیک رو بر اساس Ip port تقسیم میکنه و به محتوات پیام نگاه نمی کنه
- لایه 7 - Application Layer
درون لایه با توجه به هدر کوکی و مسیر تصمیم بگیرد
انواع بر اساس الگوریتم
-
Round Robin بر اساس توالی تقسیم می کند
-
Least Connections اونی که سرش خلوت تره
-
Consistent Hashing(IP Hash) ابتدا هش آی پی رو در میاره و همچنین اطمینان میده که یه آی دی ثابت به یه نود میره همواره ،خوبیش اینه می تونیم توی همون سرور کش بزاریم چون مطمعنیم درخواست بعدی هم به همین نود میاد
-
Weighted Round Robin سروری که ریسورس بیشتر داره و قوی تره بیشتر میگیره
مسیر Traffic Flow
- درخواست توسط مشتری ارسال میشه
- اختیاری به گیت وی میرسه و تصمیماتی مانند بلاک ، آتنتیکیشن ، ریت لیمیت و ورژن های api بررسی میشه
- به لودبالانسر میرسه و با توجه به الگوریتم ها ، درخواست رو توزیع میکنه
- دیگه به سرور رسیده و پردازش میشه
web servers
بعد از لود بالانسر ها وجود دارند و وظیفه ی لاجیک بیزینس رو هندل کنند
نکته توجه شود الزامی نداره این بخش شبیه به تقسیم بندی data model باشه ، به بیان دیگر الزامی نیست بیزینس لاجیک ما که شمال سرویس های ما هستند نظیر تیبل های دیتابیس ما باشه
**حافظه در سرور ها **
بعضی داده ها مانند سشن ها یا اطلاعات کاربر رو می تونیم ذخیره کنیم اما باید مطمعن باشیم درخواست بعدی هم به همین نود بیاد
- stateless
خود هیچ حافظه کش ندارند و از کش مرکزی استفاده می کنند
بدیش اینه که از نتورک باید استفاه کنیم و سرعت کش پایینه خوبیش اینه مدیریت راحت تر و مطمعنیم وجود داره
- statefull
هر سرور کش داخلی داره بدیش اینه از راند رابین نمیشه استفاده کرد و اگر طرف نتورکش تغییر کرد شاید دوباره باید لاگین کنه
manability
توسعه تنها بخش کد زدن و تحویل دادن پروژه نیست ، بلکه فیکس باگهای آینده ، افزودن فیچر و انجام عملیات مانند ادمین جز پروژه هست ، حال هرچقد این کار ها آسان تر باشد ، اصطلاحن نگهداری پروژه راحت تره کار هایی مانند تست نویسی ، مانیتور کردن سیستم ، همچنین افزودن به کدبیس همراه با اویلیبیلیتی ،
long running procces (task)
بعضی از درخواست ها در سیستم باید از یه سرویس پاسخ بگیرد و شاید اون سرویس پاسخش بیش از timeout درخواست باشه ، به این نوع مسائل لانگ رانینگ پراسس میگن ، و راه حل هایی برای این مسائل هست
-
timeout زیاد بشه ، راهی ساده ولی شاید استقبال نشه
-
از روش های غیر همزمان استفاده بشه ، مثلن از polling , webhook استفاده بشه و کل سیستم pend این بلاک نشه ، درخواست سعی شه در استوریج یا کش ذخیره بشه و با توجه به بیزینس ، تا یه زمان مشخص در اسنوریج باقی بمونه
در این حالت باید در نظر داشته باشیم درخواست چند بار ارسال نشه و لاک بشه اون درخواست و هر بار درخواست زده شد ، status پاسخ داده بشه همچنین باید در نظر بگیریم منابع زیادی احتمالن مصرف میشه و نباید در خواست تکراری داشته باشیم
همچنین error handling هم مشکله زیرا recover کردن و یا conpansate distribiuted transaction ها مشکله
همچنین برای کار بر گاهی نیازه ( در صورتی که تسک پردازشی مانند تبدیل ویدیو هست ) به صورت استریم ، فیدبک بدیم یعنی درصد پردازش یا استتوس بدیم بهش
برای پیاده سازی به موارد زیر نیاز داریم:
- status
هر درخواست باید وضعیتش مشخص باشه ، مثلن یک مولفه برای یونیک بودن رو در نظر میگیریم (یوزر یا شناسه درخواست) و در دیتابیس status آن را به کار بر نشان میدیم
- job scheduler
یه فانکشن وضعیت تسک رو آپدیت کنه
cache
دو روش در سیستم دیزاین وجو دارد
Distributed Cache Layer
در این روش نود های کش در لایه ی جدا هستند ، هر سرویس اگر نیاز داشته باشد ، باید از این لایه درخواست بزند
-
مزایا مدیریت کش سوای سرویس و منطق است ، تنها مانند سرویس بیرونی کافی است کال شود ، مطمعنیم که داده در صورت وجود در کش ، قابل دریافت است و امکان ندارد در جای دیگر باشد
-
معایب برای هر در خواست از نود خارج شده و در شبکه ترافیک ایجاد کرده و سرعت پاسخ بسته به شبکه دارد
Local Cache in Each Node
دقیقا تمام موارد بالا برعکس است ، هر نود درون خود کش دارد ، احتمال دارد داده درون کش نود نباشد و درون کش نود دیگر باشد ، اما به دلیل این که درون خود os هندل میشود و درخواست به شبکه نمی رود خیلی سریع تر است
به نظر خودم اگر بتوان با الگوریتم هایی مانند shard key یا ip hash مطمعن بود که هر درخواست دقیقن باید به کدام نود برود ، و لود بالانسر بهینه در خواست ها را تقسیم کند ، خیلی کش داخلی بهتر است
algorithm caching
اینا زمانی هست که حجم مموری برای کش پر شده و قرار داده پاک کنیم
-
least recently used
-
first in first out
-
least frequently used
provider/3rd party
در آموزش ها این بخش رو بلک باکس میبینن
- notification service
در بعضی از طراحی ها هم این دیده شدهو به عنوان پروایدر بیرونی یا 3rd party دیده میشن مانند firebase
- geo
برای دریافت نقشه ی مپ نام خیابان ها استفاده میشود ، همچنین برای دادن نقطه lat , lon و دریافت آدرس آنجااسم خیابان ها و برعکس
دو الگوریتم مهم داره
-
- quad trees
میاد نقشه ی جهان رو تقسیم بر ۴ می کنه و هر کدوم رو بر اساس ماتریس نام گذاری می کنه ، سپس هر صفحه رو دوباره تقسیم بر ۴ می کنه و نامش با پسوند نام پدر شروع می شه و ذخیره میشه برای ذخیره کردن هم مانند درخت که هر نود ۴ فرزند دارند اجام میگیرد
system design example
url shortner
یک سرویس که از کاربر ورودی ، یک لینک می گیره و توی دیتابیسش ذخیره می کنه و کلید اون رو میبره توی مبنای ۶۲ و خروجی رو تحویل کاربر میده
زیرا مبنای ۶۲ هم داخل url قابل پیاده سازیه چون خیلی از کارکتر های کد اسکی توی url نمی شه استفاده کرد ، هم به زمان انسانی خیلی نزدیکه (حروف بزرگ - کوچی و اعداد)
آن را داخل تیبل های دیتابیس ذخیره می کنیم ، حال اگر کار بری در خواست ورودی به یک سایت زد و کدی همراه داشت ، آن را ابتدا تغییر می دیم به مبنای ۱۰ و آن را از دیتابیس ورمیداریم و کاربر روی ریدایرکت میکنیم به سایت مورد نظر
reference
یه مارکداون فارسی و جذاب